Notes from ACM HPC Summer School 2022
Notes from the ACM Summer School on HPC I attended in Barcelona in 2022, hosted by BSC and UPC. Four days of lectures spanning RISC-V processors for ML, vector extensions, distributed data analysis, and energy efficiency in HPC. Highly recommended for junior graduate students working on HPC.
Day 1: Specializing Processor for ML (RISC-V)
By Prof. Luca Benini (ETH Zurich)
1.1 Single Core
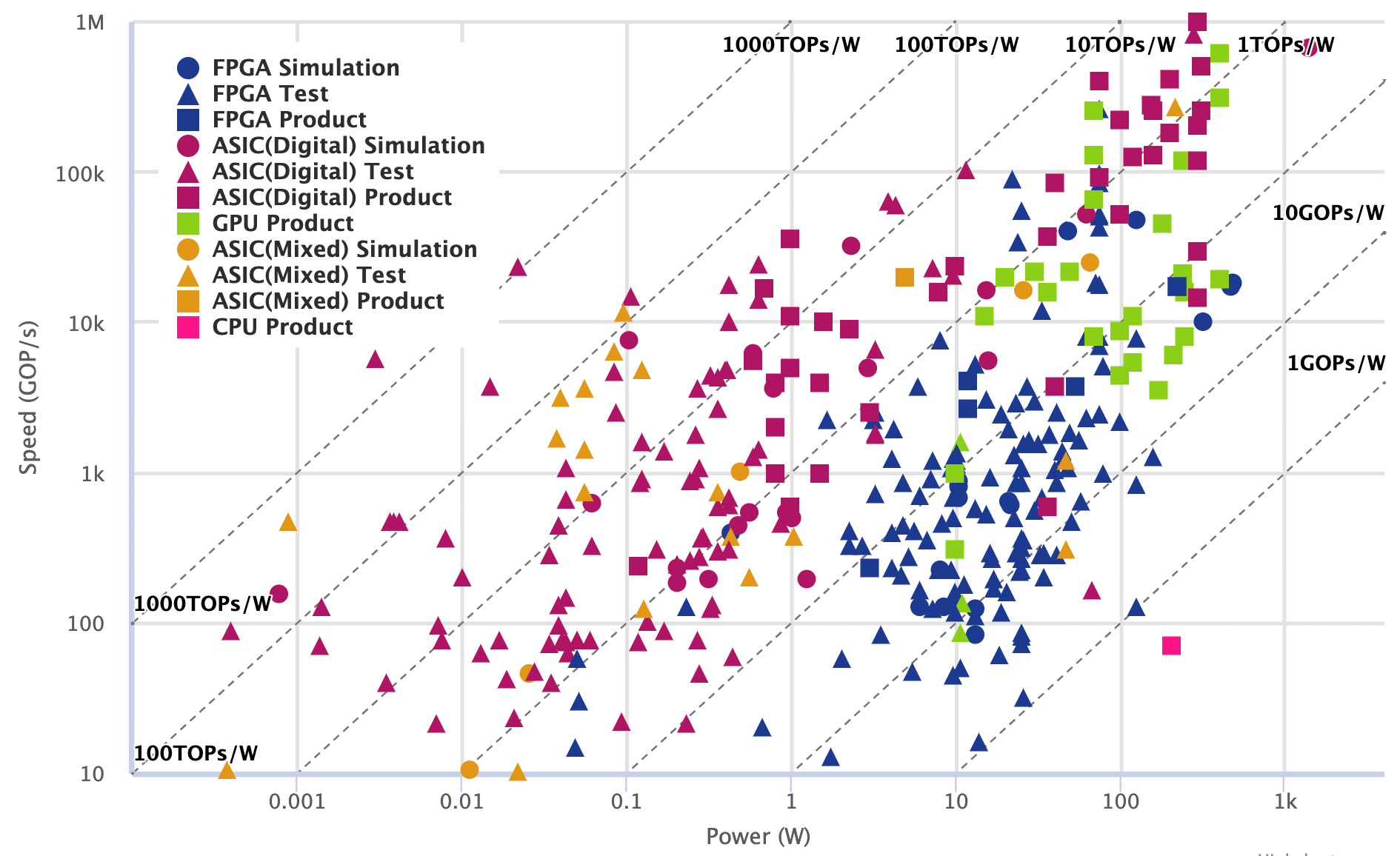
- Observation: higher performance → less energy efficient
- Eg: if a new high-performance processor requires 2x power to finish a workload, it must be at least 2x faster for the optimizations to be energy-saving
1.1.1 “Classical” core performance scaling trajectory
- Faster CLK → Deeper pipeline → IPC drops
- Recover IPC → superscalar → ILP bottleneck (dependencies)
- Mitigate ILP bottlenecks → out-of-order execution → huge power and area cost!
1.1.2 RISC-V Instruction Set Architecture
- Started by UC-Berkeley in 2010
- Contract between SW and HW
- Partitioned into user and privileged spec
- External Debug
- Standard governed by RISC-V foundation
- Defines 32, 64 and 128 bit ISA
- No implementation, just the ISA
- Different implementations (both open and close source)
1.1.3 RISC-V Arch States
- 32 regs, each 32/64/128 bits long
- 1 program counter
- Byte addressing
- FP ops: 32 additional regs
- Control status registers (CSRs)
1.1.4 RISC-V is a load/store architecture

- All operations are on internal registers
- Can not manipulate data in memory directly
- Load instructions to copy from memory to registers
- R-type or I-type instructions to operate on them
- Store instructions to copy from registers back to memory
- Branch and Jump instructions
1.2 From Single Core to Multi-Core
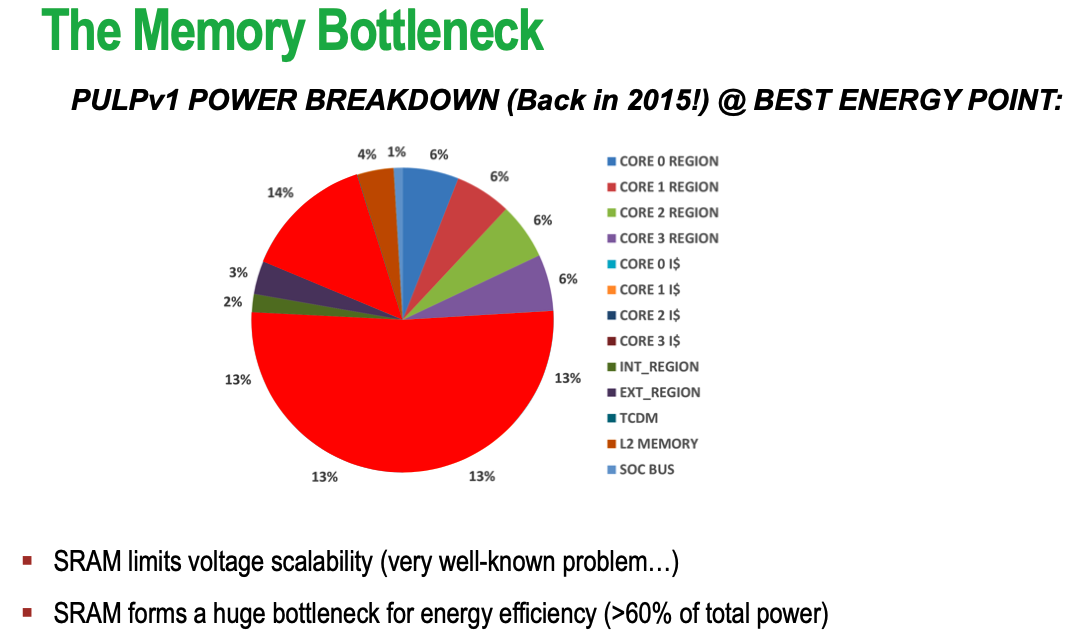
1.2.1 Memory bottleneck from single core to multi-core
1.2.2 Multiple buffering
The use of more than one buffer to hold a block of data, so that a “reader” will see a complete (though perhaps old) version of the data, rather than a partially updated version
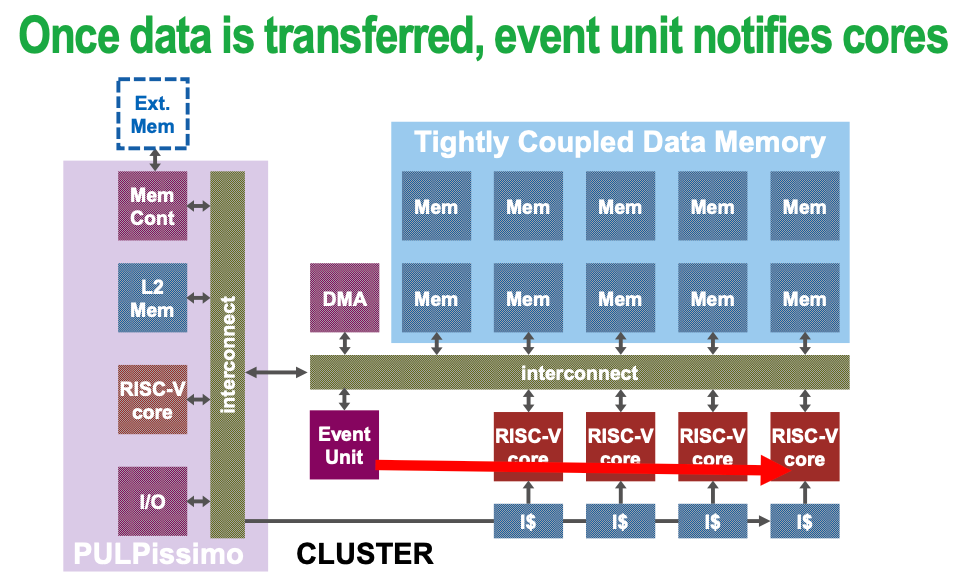
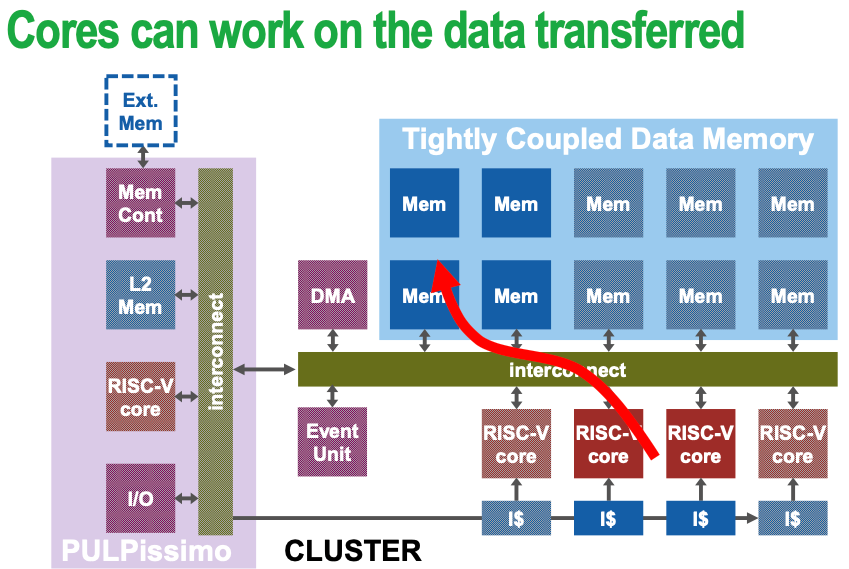
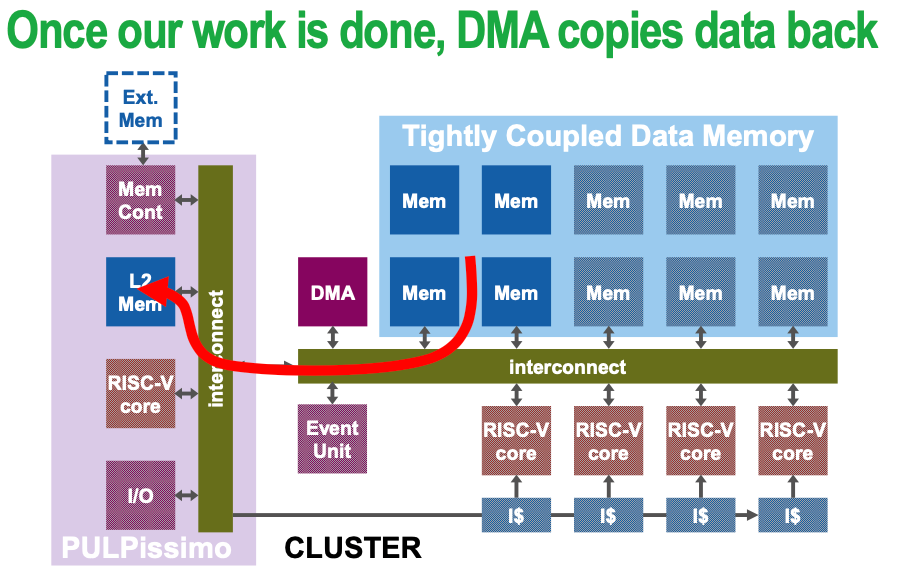
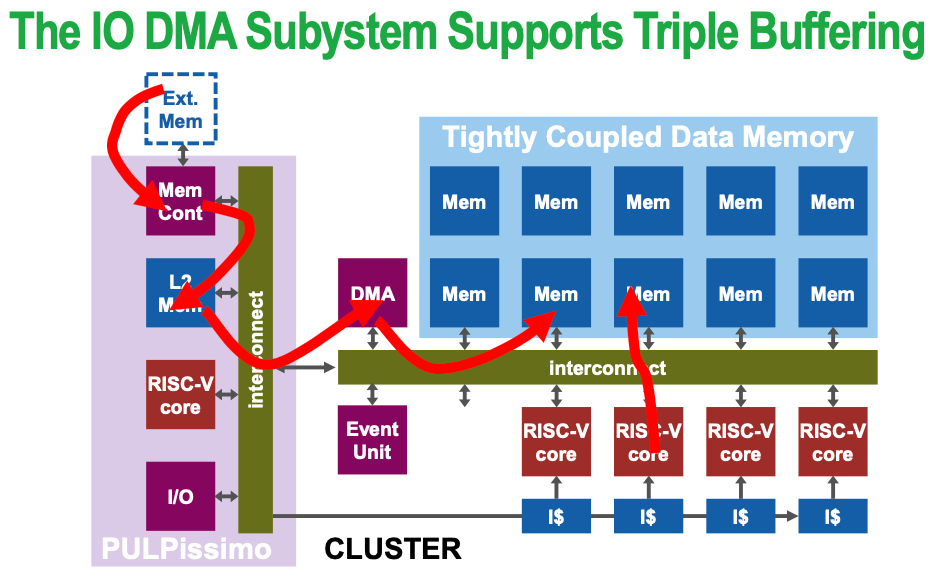
Possible issue — bank conflict Multiple simultaneous accesses to a bank result in a bank conflict
Solution: serialization
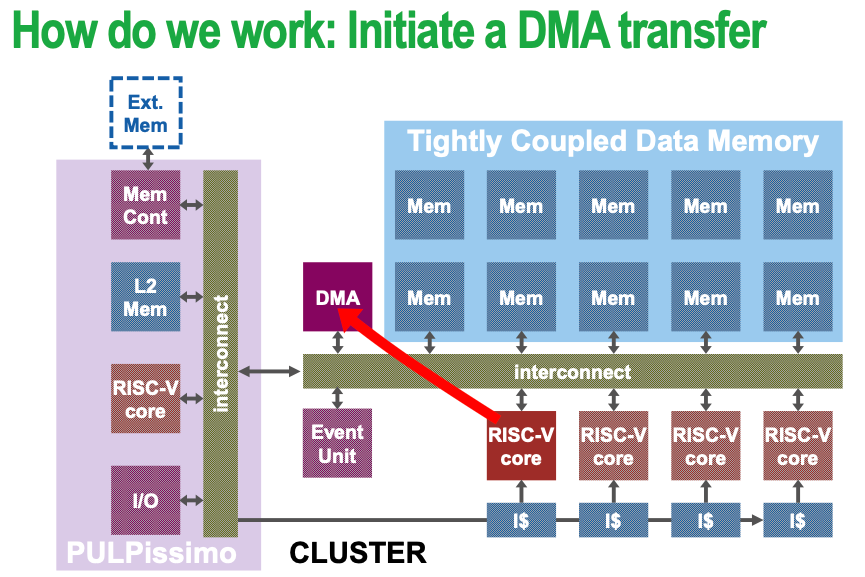
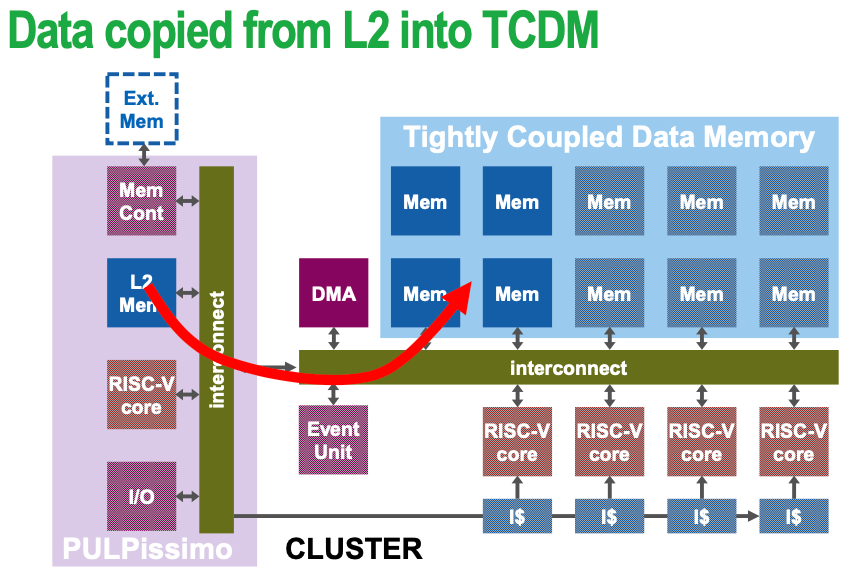
1.2.3 Tightly coupled accelerator
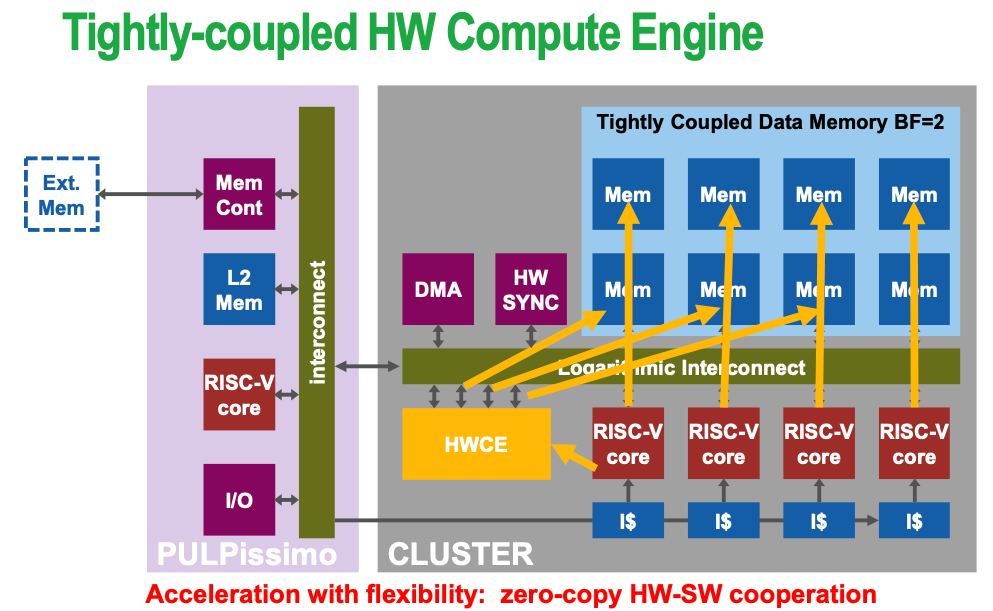
Key characteristic: share L1-cache access with RISC core, thus no data copy is needed (zero-copy)
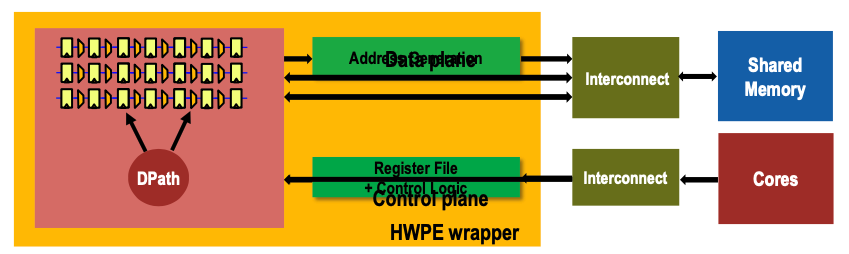
- Hardware Processing Engine efficiency vs. optimized RISC-V core
- Specialized datapath (e.g. systolic MAC) & internal storage (e.g. linebuffer, accum-regs)
- Dedicated control (no I-fetch) with shadow registers (overlapped config-exec)
- Specialized high-BW interconnect into L1 (on data-plane)
1.3 Large-Scale ML
1.3.1 Trend in the Industry
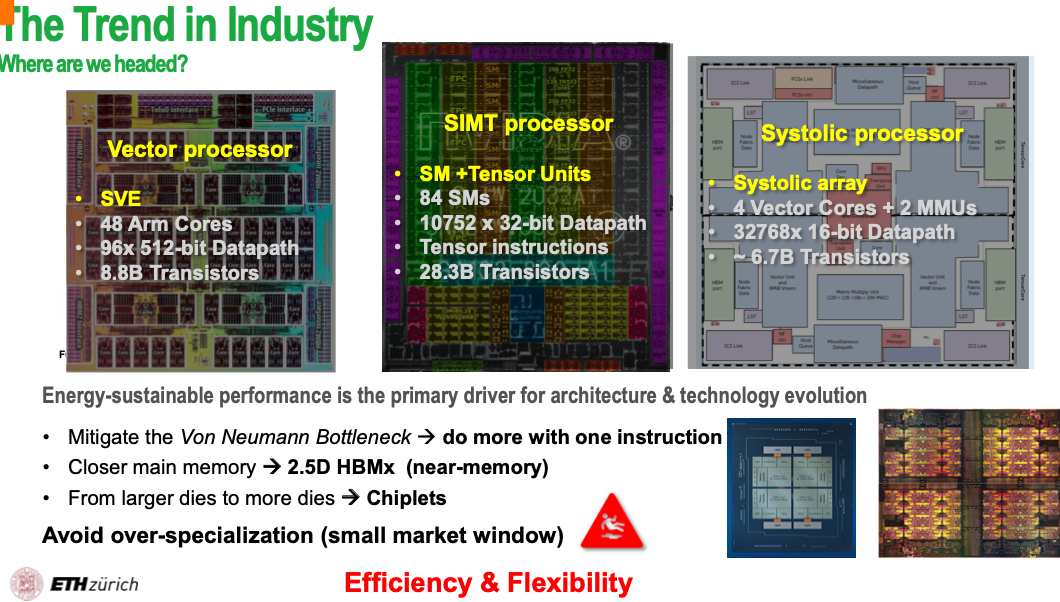
von Neumann bottleneck
The idea that computer system throughput is limited due to the relative ability of processors compared to top rates of data transfer
Key design questions: sharing or copying the memory between processors?
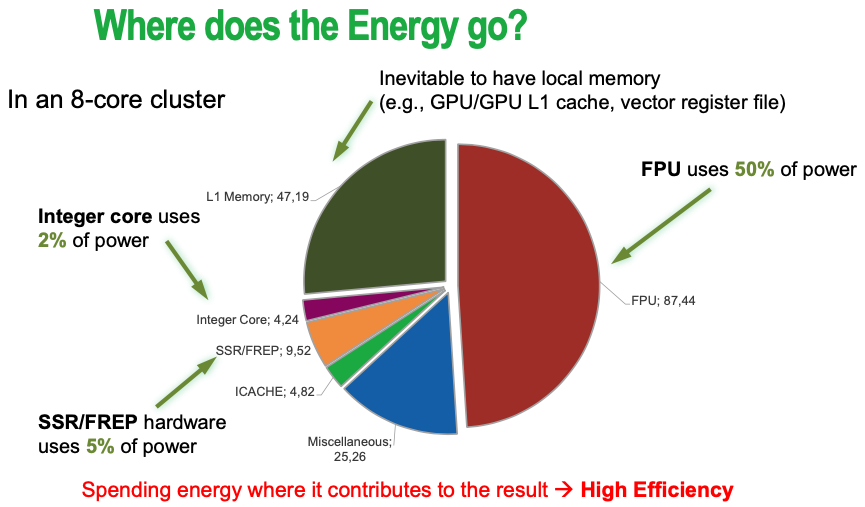
1.3.2 Energy consumption breakdown
Day 2: RISC-V Vector Extensions
by Prof. Jesús Labarta & Roger Ferrer (BSC)
- Restrictions when using the modern compilation system on RISC-V
- Only one registers — need to adapt the register allocation scheme
Day 3: Distributed Data Analysis
By Prof. Rosa M. Badia (BSC) and Dr. Josep LL. Berral (UPC)
PyCOMPs&COMPs
- Master-worker architecture
- Start on master, and task is offloaded to workers
- Need manual annotations on the types of data
- INOUT: read and write at the same time
- Facilitate parallelising decisions by runtime
- Runtime decides how to parallelize
- Support persistent memory, streaming data, http etc
Spark
- Lazy execution: Spark does not compute the value if they are not used (only defined)
- Scala
- val: static
- var: dynamic, can be re-assigned
Day 4 - Energy Efficiency in HPC
4.1 Customised vector acceleration
by Prof. Mauro Olivieri (Rome Sapienza University)
- Energy per cycle (dynamic only): $C_{eff}*V^2$
- Energy per operations: $C_{eff}* V^2 * CPI$ (usually measured in J/op)
- There is a trade-off btw propagation delay and power: Increase the voltage → Increase clock frequency
4.2 Techniques to accelerate the applications
4.2.1 Pipelining
After some point, adding more pipeline stages no longer improves power efficiency
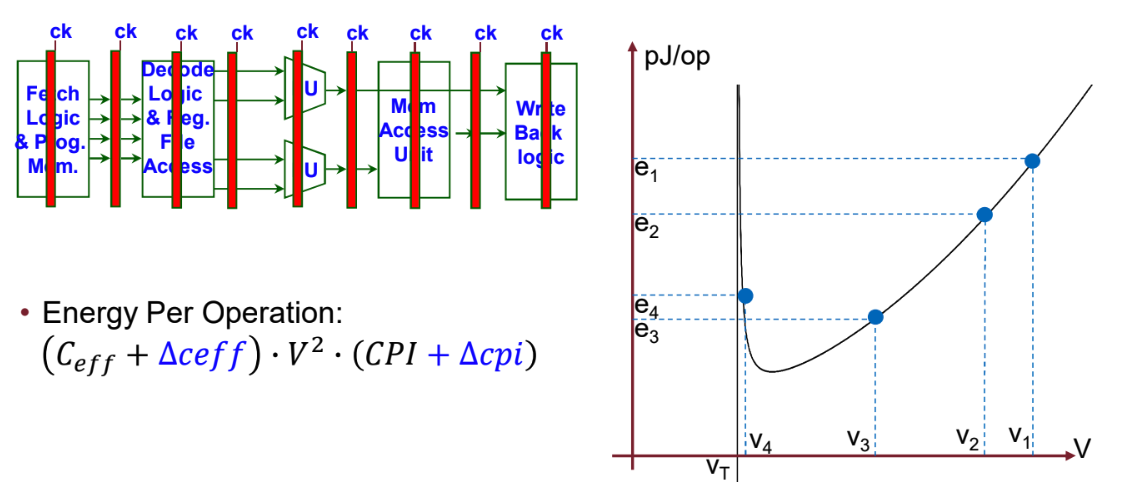
- Cost of switching the pipeline
- Pipeline penalty due to data dependency
CPI never remains the same when pipe depth increases (i.e.when logic depth decreases)
- In general, the CPI degradation (i.e. average instruction latency
increase) is proportional to the pipeline latency
- E.g. half the logic depth => double branch penalty latency
- E.g. pipelining memory access is not as feasible as logic (hard macro, memory IP compiler) => memory access latency grows
- Exception to this rule (with ideal microarchitecture design!): fully interleaved independent threads (perfect “barrel processor”)
- When thread count > maximum stall latency, it is theoretically possible to maintain the CPI untouched
- In general, the CPI degradation (i.e. average instruction latency
increase) is proportional to the pipeline latency
4.2.2 Parallelisation
4.2.3 Hardware-acceleration
Why?
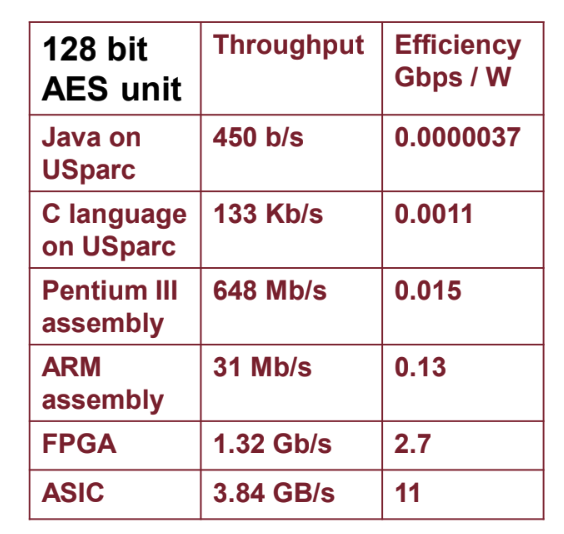
- Save a lot of instructions fetch
- No need to decode (most of) the instructions
- As a result, CPI is reduced
- Voltage can be reduced to save power, but it will add noise to the gates and affect the data stored
4.2.4 Types of accelerators
- Instruction-mapped: co-processor
- Offload complex operations
- Memory-mapped: loosely-coupled processor
- Offload entire kernels (eg: conv kernels)
- More efficient, more complex
Note: How to collect the energy consumptions
- Gate simulators: only related order is needed
- FPGA: real measurement of current and voltage.
- P = V*A
- Energy = intergrate power over time
4.3 Energy Efficient HPC Applications
by Valerie Taylor (ANL)
4.3.1 Power Saving Techniques
- Hardware-based
- Dynamic resource sleeping
- Energy efficient processor and memory
- Software-based
- Dynamic voltage and frequency scaling (DVFS) $p\propto cv^2f$
- Dynamic concurrent throttling (DCT)
- Application-based
- Utilise hardware counters for hints
- Power capping
- Execution time
- Loop unrolling
- Reduce branch misprediction
- Eliminate some conditional branches
- Vectorisation
- Change page size
- eg: change TLB
- Goal: less page miss via appropriate page size
- Blocking
- In-line procedures
- Reduce the # of HW interrupts
- Loop unrolling
4.3.2 Ways to reduce energy
- Reduce time and power
- Code modification
- Compiler flags
- Loop unrolling
- TBL size
- DCT
- DVFS
- Code modification
- Reduce time and increase power
- Decrease runtime via an increase in resource utilisation
- As long as the reduction in time is greater than the increment in power
- Reduce power and increase time
- DVFS
4.3.3 Profiling tools
- Performance Application Programming Interface(PAPI)
4.3.4 Dynamic Power Capping
- Runtime increase w.r.t. power reduction:
- $\delta$ increase: bursty < piecewise < smooth power applications
Dennard Scaling: Power technology does not support any more power reduction at constant die area and feature size scaling is stalling.