Ziji's Homepage
Ziji's Homepage
Home
Publication
Blog Post
Project
Light
Dark
Automatic
1
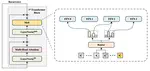
Tetris: Efficient and Predictive KV Cache Offloading for Agentic and Reasoning Workloads
We present a predictive KV cache offloading mechainism that support ultra-long decoding phase in reasoning and agentic workloads.
Ziji Shi
,
Chaoyi Ruan
,
Penghui Qi
,
Guangxing Huang
,
Xinyi Wan
,
Min Lin
,
Jialin Li
PDF
Cite
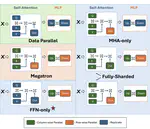
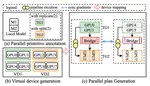
TAPAS: Fast and Automatic Derivation of Tensor Parallel Strategies for Large Neural Networks
We present a framework that drastically speeds up the process of deriving the tensor parallel schedule for large neural networks by 160x.
Ziji Shi
,
Le Jiang
,
Ang Wang
,
Jie Zhang
,
Chencan Wu
,
Yong Li
,
Xiaokui Xiao
,
Wei Lin
,
Jialin Li
PDF
Cite
Poster
ParaGAN: A Scalable Distributed Training Framework for Generative Adversarial Networks
We present ParaGAN, a cloud-training framework for GAN, which demonstrates near optimal scaling performance over thousands of acclerators with system & training co-design.
Ziji Shi
,
Jialin Li
,
Yang You
PDF
Cite
Poster
Whale: Efficient Giant Model Training over Heterogeneous GPUs
Whale is a highly scalable and efficient distributed training framework for deep neural networks, introducing a hardware-aware parallel strategy and user-enabled model annotations for optimising large-scale model training, demonstrating its prowess by successfully training a multimodal model with over ten trillion parameters on a 512-GPU setup.
Xianyan Jia
,
Le Jiang
,
Ang Wang
,
Wencong Xiao
,
Ziji Shi
,
Jie Zhang
,
Xinyuan Li
,
Langshi Chen
,
Yong Li
,
Zhen Zheng
,
Xiaoyong Liu
,
Wei Lin
PDF
Cite
Code
Slides
Going Wider Instead of Deeper
We propose an efficient parameter sharing strategy for Transformer architecture by replacing FFN with MoE layer and sharing the trainable parameters except the normalization layers. Competitive performance across CV and NLP tasks were achieved with up to 6x reduction in the numbers of unique parameters.
Fuzhao Xue
,
Ziji Shi
,
Futao Wei
,
Yuxuan Lou
,
Yong Liu
,
Yang You
PDF
Cite
Cite
×