ParaGAN: A Scalable Distributed Training Framework for Generative Adversarial Networks
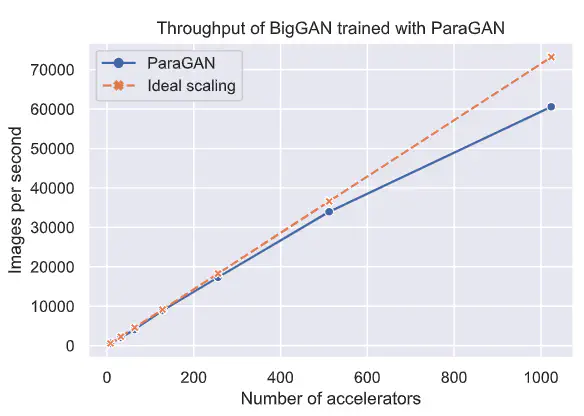 ParaGAN scales to 1024 TPU cores at 91% scaling efficiency.
ParaGAN scales to 1024 TPU cores at 91% scaling efficiency.Abstract
Recent advances in Generative Artificial Intelligence have fueled numerous applications, particularly those involving Generative Adversarial Networks (GANs), which are essential for synthesizing realistic photos and videos. However, efficiently training GANs remains a critical challenge due to their computationally intensive and numerically unstable nature. Existing methods often require days or even weeks for training, posing significant resource and time constraints.
In this work, we introduce ParaGAN, a scalable distributed GAN training framework that leverages asynchronous training and an asymmetric optimization policy to accelerate GAN training. ParaGAN employs a congestion-aware data pipeline and hardware-aware layout transformation to enhance accelerator utilization, resulting in over 30% improvements in throughput. With ParaGAN, we reduce the training time of BigGAN from 15 days to 14 hours while achieving 91% scaling efficiency. Additionally, ParaGAN enables unprecedented high-resolution image generation using BigGAN.