Abstract
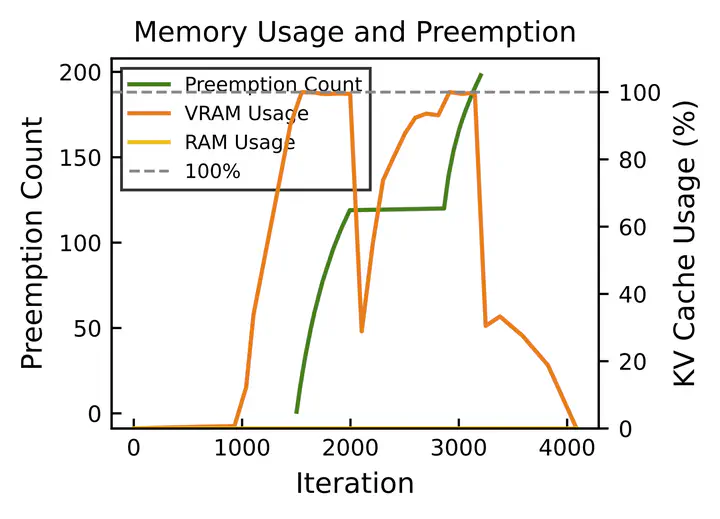
Inference-time scaling and tool-calling enhance LLM reasoning and agentic capabilities but greatly increase key–value (KV) cache usage, especially for long intermediate reasoning steps and API call histories. While prior work has addressed long input handling, long output scenarios remain underexplored. We identify cascading preemption, where successive preemptions occur due to uninformed victim selection, degrading time-per-output-token (TPOT) performance.
We present Tetris, an inference system for agentic and reasoning workloads that mitigates cascading preemption through (1) light weight per-token sequence length prediction, (2) trade-off–driven recomputation vs. offloading, and (3) layerwise asynchronous KV cache transfer with predictive scheduling. Our analysis shows that offloading is asymptotically more efficient for long sequences, and our implementation in vLLM significantly reduces preemption frequency and improves P99 TPOT in memory-constrained settings.