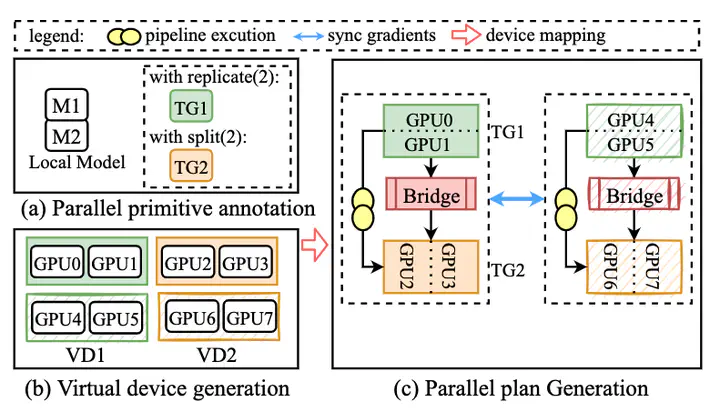
 System overview of Whale.
System overview of Whale.Abstract
Scaling up deep neural networks has been proven effective in improving model quality, while it also brings ever-growing training challenges including training efficiency, programmability, and resource adaptability. We present Whale, a general and efficient distributed training framework for giant models. Whale generalizes the programming interface to support various parallel strategies and their hybrids through defining two new primitives as model annotations to engage user cooperations. The Whale runtime utilizes those annotations and performs graph optimizations to transform a local deep learning DAG graph for distributed multi-GPU execution. Whale further introduces a novel hardware-aware parallel strategy, allowing the training of giant models on heterogeneous GPUs in a balanced way. Deployed in a production cluster with 512 GPUs, Whale successfully trains an industry-scale multimodal model with over ten trillions model parameters, named M6, demonstrating great scalability and efficiency.