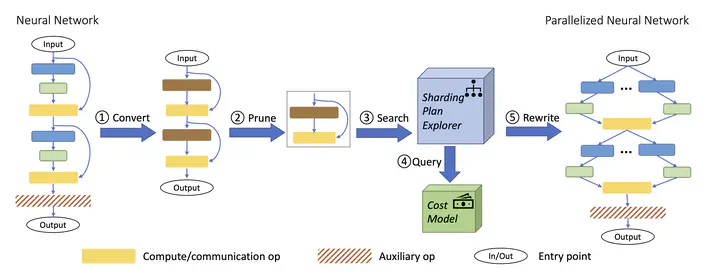
 Overview of TAP. TAP takes a neural network as input and outputs the best tensor parallel schedule.
Overview of TAP. TAP takes a neural network as input and outputs the best tensor parallel schedule.Abstract
Model parallelism is essential to train large language models efficiently. However, determining the optimal model parallel schedule for a given neural network can be slow and inefficient due to the vast choice space. To address this challenge, we propose a tensor model parallelism framework called TAP, which automatically searches for the best data and tensor parallel schedules. Our approach is based on the observation that a neural network can be represented as a directed acyclic graph, within which only exists a limited set of frequent subgraphs. With that, we design a graph pruning algorithm that efficiently folds the search space. As a result, TAP runs at sub-linear complexity with respect to model size, which makes it a practical solution for large-scale networks. Experimental results demonstrate that TAP outperforms the state-of-the-art automatic parallelism frameworks by 20-160x in searching time. Moreover, the performance of TAP’s discovered schedules is competitive with expert-engineered ones. In summary, TAP provides a powerful and efficient tool for model parallelism that can help alleviate the burden of manual tuning.