Ziji's Homepage
Ziji's Homepage
Home
Publication
Blog Post
Project
Light
Dark
Automatic
MLSys
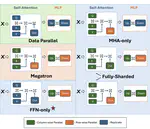
TAPAS: Fast and Automatic Derivation of Tensor Parallel Strategies for Large Neural Networks
We present a framework that drastically speeds up the process of deriving the tensor parallel schedule for large neural networks by 160x.
Ziji Shi
,
Le Jiang
,
Ang Wang
,
Jie Zhang
,
Chencan Wu
,
Yong Li
,
Xiaokui Xiao
,
Wei Lin
,
Jialin Li
PDF
Cite
Poster
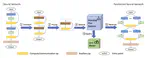
ParaGAN: A Scalable Distributed Training Framework for Generative Adversarial Networks
We present ParaGAN, a cloud-training framework for GAN, which demonstrates near optimal scaling performance over thousands of acclerators with system & training co-design.
Ziji Shi
,
Jialin Li
,
Yang You
PDF
Cite
Poster
TAP: Efficient Derivation of Tensor Parallel Plans for Large Neural Networks
We present a framework that drastically speeds up the process of deriving the tensor parallel schedule for large neural networks.
Ziji Shi
,
Le Jiang
,
Jie Zhang
,
Xianyan Jia
,
Yong Li
,
Chencan Wu
,
Jialin Li
,
Wei Lin
PDF
Cite
Poster
Cite
×